
개발 블로그
[공학연구실습2/1주차]머신런링/딥러닝 모델 성능 분석 본문
머신러닝/립더닝 모델의 성능 분석에 필요한 용어 정리
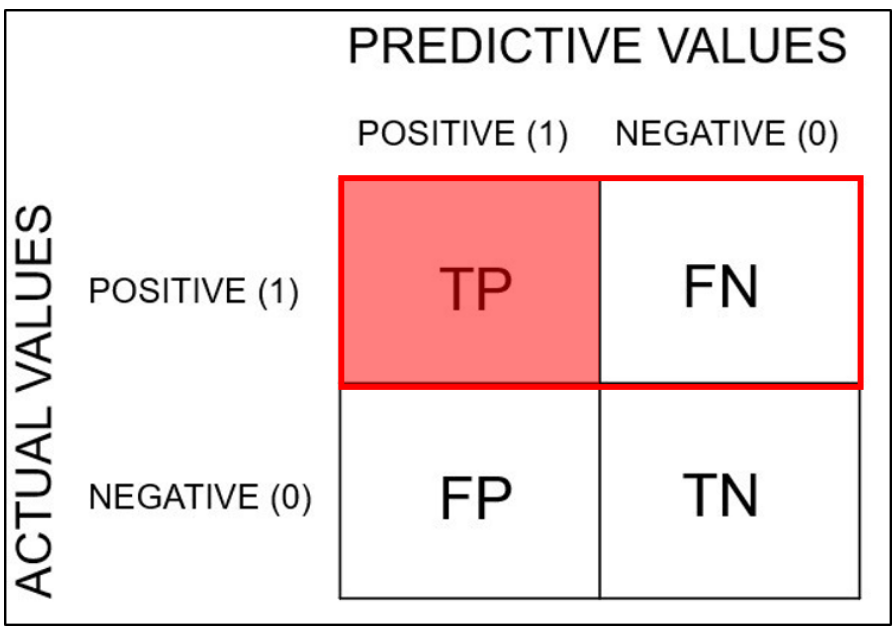
1. Confusion matrix(오차 행렬)
training을 통한 모델의 예측 성능을 측정하기 위해 예측값과 실제값을 비교하기 위한 표

true/false: 실제와 예측이 일치하는가?
positive/negative: 무엇으로 예측했는가?
- TP(True Positive): 실제는 positive인데, positive로 예측
- FN(False Negative): 실제는 positive인데, negative로 예측
- FP(False Positive): 실제는 negative인데, positive로 예측
- TN(True Negative): 실제는 negative인데, negative로 예측
이 4가지 값들을 조합해 precision, recall 값을 계산한다.
2. accuracy(정확도)
모델이 바르게 분류한 비율 (정답 비율)


3. precision(정밀도)
모델이 positive로 예측한 것 중 실제값이 positive인 비율
ex) yes라 예측할 때, 얼마나 정확한가?를 측정


4. recall(재현도)
실제값이 positive인 것 중 모델이 positive라 분류한 비율

5. F1 score
precision와 recall의 조화평균으로, 두 가지 지표를 균형 있게 반영하는 지표이다.


accuracy가 아닌 F1 score를 쓰는 경우는 데이터가 불균형할 때이다.
데이터가 불균형할 때 accuracy로 모델을 평가하면 올바르게 측정하기 힘들지만 F1 score로 모델을 평가하면 비교적 정확하게 측정할 수 있다.
참고
저번 시간에 진행했던 ANN와 CNN 모델의 결과를 바탕으로 성능 분석 지표에 따라 두 모델의 성능을 비교해보자.
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score
y_pred=model.predict(x_test)
y_pred=np.argmax(y_pred, axis=1)
y_test=np.argmax(y_test, axis=1)
ann_ConfusionMatrix=confusion_matrix(y_test, y_pred)
print(ann_ConfusionMatrix)
- 먼저 predict 함수로 x_test 데이터를 이용해 모델을 예측한다.
- 그리고 argmax 함수를 사용해 데이터 형식을 바꿔준다. 이때 argmax 함수란 input 집합 중에서 가장 큰 값의 index를 output으로 내보내는 함수이다. 즉 예측한 데이터 중에서 가장 큰 값의 index를 output으로 꺼낸다.

- 그리고 예측값과 실제값으로 confusion_matrix 함수를 이용해 confusion matrix를 출력한다.
결과

결과의 confusion matrix의 행이 실제값이고 열은 예측값이다. (0, 0)에 위치한 것이 의미하는 것은 실제 0인데 0으로 예측한 데이터 양(1)을 말한다. (0, 1)에 위치한 것은 실제값이 0인데 모델이 1로 예측을 한 데이터를 말한다. 그리고 (5, 8)은 실제값이 8인데 5로 예측한 데이터를 말한다.
p = precision_score(y_test, y_pred, average=None)
r = recall_score(y_test, y_pred, average=None)
f1 = f1_score(y_test, y_pred, average=None)
print("precision_score: ", p)
print("recall_score: ", r)
print("f1_score: ", f1)그리고 precision, recall, f1 score를 출력한다.
결과

이와 동일하게 CNN 모델의 confusion matrix를 출력한다.
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score
y_pred=model.predict(x_test)
y_pred=np.argmax(y_pred, axis=1)
y_test=np.argmax(y_test, axis=1)
cnn_ConfusionMatrix=confusion_matrix(y_test, y_pred)
print(cnn_ConfusionMatrix)
결과

확실히 ANN보다 CNN 모델의 예측이 정확하다. 하지만 아직 이 데이터만으로는 ANN 모델과 CNN 모델의 성능을 비교하긴 어려워 보인다.
CNN 모델의 여러 성능 지표를 출력한다.
p = precision_score(y_test, y_pred, average=None)
r = recall_score(y_test, y_pred, average=None)
f1 = f1_score(y_test, y_pred, average=None)
print("precision_score: ", p)
print("recall_score: ", r)
print("f1_score: ", f1)
결과

vs
이를 토대로 ANN과 CNN을 비교하면 ANN보다 CNN의 성능 지표들이 더 좋은 결과를 가진다.
따라서 CNN이 더 좋은 성능을 가진다고 볼 수 있다.
'전공 공부 > 공학연구실습' 카테고리의 다른 글
| [공학연구실습2/1주차] 강화학습이란 (0) | 2022.11.22 |
|---|---|
| [공학연구실습2/1주차]VSCode에서 Tensorflow 환경 구축 (0) | 2022.11.22 |
| [공학연구실습2/1주차]딥러닝 프레임워크 활용법(Keras/TF 또는 PyTorch 사용) (0) | 2022.11.11 |
| [공학연구실습2/1주차]Keras로 ANN,CNN 구현 (0) | 2022.11.03 |
| [공학연구실습2/1주차]openAI/Keras/ANN/CNN이란? (0) | 2022.11.03 |


